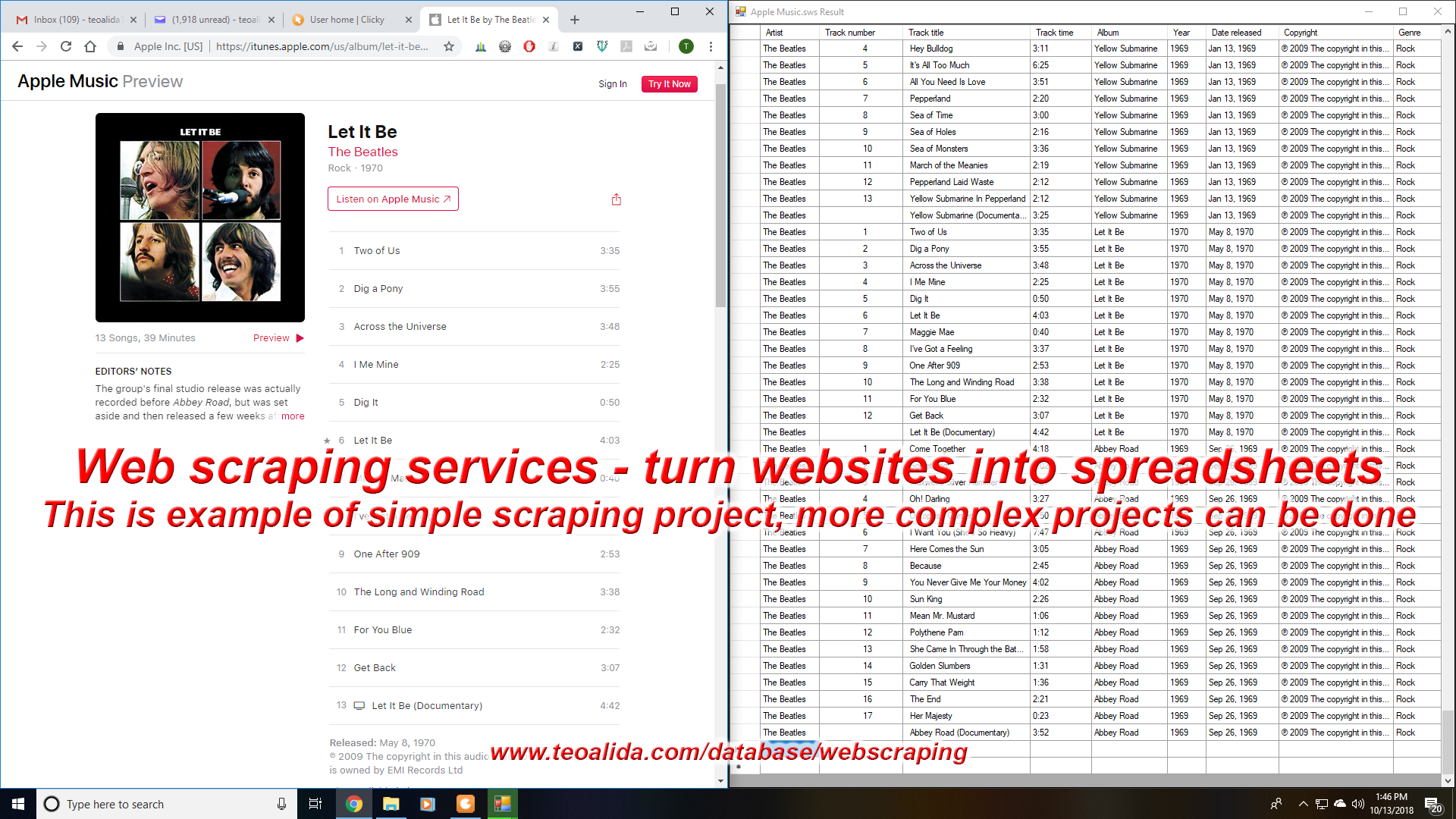
If you are building a website, a mobile app, or just require specific data but cannot find in usable format, just give me link to a website having required data, we can code a scraper bot that visit a list of given pages, copy specific data from each page and put it in an Excel / CSV file automatically, at rate of few pages per second (watch the video), then sell database to you and future customers needing the same.
Note: I prioritize projects based on number of people interested in each database. I am NOT a freelancer that you can hire anytime you want, I am a data provider creating USEFUL databases that I can sell via website to as many people is possible. Since 2015 to 2018 I created over 50 databases via scraping, it became difficult to keep updates on-going for all, so I had to abandon databases with less than 5 sales per year, and reject new projects that takes more than 1 hour of coding + 5 hours of scraping, if the data collected have NO USE for anyone else than yourself (sometimes I ask my friends to do your project in my place). See examples of projects done and their price.
a
For many years, manual data entry in Excel (sourcing from books, as seen in this video) or manual copy-pasting from websites, was the only way I created databases. A slow process which limited the size of the databases I could make. Even in this slow process I made about 40 databases in the fields of personal interest: automobiles, geography, real estate, computers, gaming, etc, from pure hobby.
I started in web scraping in August 2015 when I found import.io (a free scraper for simple HTML websites), and in November 2015 I allied with a programmer to create custom scrapers for more complex websites. This allowed me to create large databases with minimum effort, in a matter of hours.
import.io turned into a paid service in April 2016 and suspended my free account. New sign-ups were limited to 500 pages/month in free plan, paid plans prices were increased in 2017 to $299/month to scrap up to 5000 pages. This gave idea to my programmer to develop own “universal” scraping software in Visual Studio, comparable with the tools available online, but with no limit in number of pages or simultaneous projects, this allow me to scrap any simple website at lower price that you can do yourself.
Once I mastered my scraping skills, in early 2016 I wrote this article to offer freelance scraping services. In 2016 and 2017 I was doing every project that was technically feasible… until I overloaded myself with responsibility to provide regular updates for about 50 projects. In 2018 abandoned databases having less than 5 sales per year so I can focus on the ~20 best-selling databases that produce 80% of my income.
Note: you CAN scrap yourself using tools like import.io, some are free but slow and limited in functionality, limited in one project at time, limited number of pages you can extract, unless you upgrade to paid subscription. Although you can scrap yourself for free (small number of pages), may take few days to learn to use efficiently these tools. Most people do not have time to learn or cannot pay expensive monthly subscription. I can help you!
Simple data scraping service
This apply on websites with a distinct URL for each page and all data in HTML code. Data can be extrated with our “universal” scraper, analyzing website and writing codes that indicate what data to extract takes usually 10 min – 1 hour. Indicative prices:
- Number of pages to be extracted: 1,000 pages = $50, 10,000 pages = $100, 100,000 pages = $300 (average speed 1 second per page, if website is slower I may charge higher) since each website have a random number of pages, these prices are just relative and final price will be given at request.
- Number of columns to be extracted = 50 cents per column.
- Multi-level scraping = $10 per level. Many car websites require a scraper for makes pages to get models URL, a second scraper for model pages to get versions URL, a third scraper to get in versions pages to extract car details which is what you need. Infinite scrolling, pagination, enter data in search boxes also add few $.
- Cleaning data after scraping = extra $ if raw data from scraper include annoying spaces and line breaks, or unwanted characters such as unit of measurement after value, which need to be removed with Excel find-replace.
You NEED to provide website URL and I will quote a price in your preferred currency (USD, EUR, GBP, AUD, SGD, etc). For example for scraping Parkers.co.uk seen in demonstration video, 1-level scraping, 101 pages to be extracted, 4 columns, no cleaning needed, I charged only €23.66 which is the number of rows (2366 rows).
 a
aComplex data scraping service
This apply on websites having drop-down lists, search boxes, JSON data, a login is required to access data, selecting various items do not produce a different URL, etc. In this case online scraping tools do not work, my friend universal scraping software also do not work, so he need to make in Visual Studio a custom scraper just for that particular website, this may take few days depending by his available time.
News: in 2019 other 2 people, from India and Australia, joined to take web scraping projects that are too complex for me.
Price: usually within $200 to $500 range which I share with my partner, price vary depending by complexity of website rather than number of pages to be extracted.
For less than 200 records may be faster to copy-paste manually than coding a custom scraping software.
Complex scraping services sometimes require screenshots (as below) for my programmer to understand how to program bot, where to click and what data to extract.
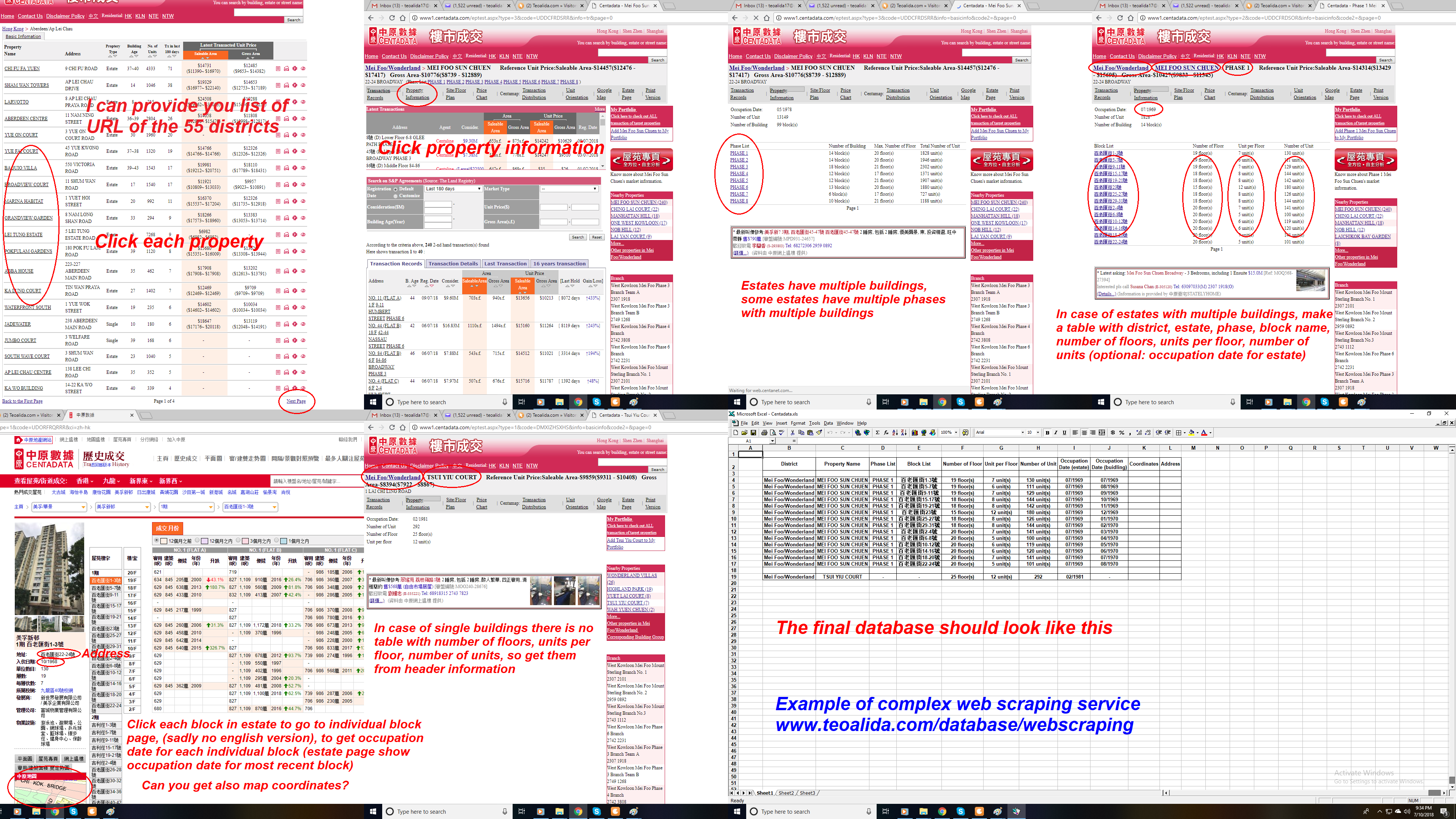 a
aNEW: Python scraping API
In 2019 another programmer joined my team, he is making scrapers in Python and run them on a server on scheduled basis (daily, weekly, monthly, etc). He may charge higher than me for initial coding, but give you an username/password to login in server and download data anytime you want, for a small monthly/yearly fee.
So if you need frequent updates, he is a cheaper option than me running scraper in my computer thus you need to pay each update (unless other customers buy same database).
Programmer turned not serious, making promises and disappearing (at least he didn’t charged money in advance), and since 2022 he was not seen online anymore.
What cannot be scraped
Theoretically I can scrap data from any website, but only websites having the required data in a consistent structure from page to page, can produce a good usable database. An example of non-consistent website is Wikipedia, trying to make a database of cities I successfully extracted city name and GPS coordinates because they are at top of every page, but I did not succeeded to extract population because it is varying in position in each city info box.
Some websites look simple to scrap, but after starting job I get IP blocked, a CAPTCHA page, etc, anti-scraping features made to prevent copying data or to prevent DDOS attacks. If you ask for price before starting the job, you should be prepared for price changes if I find anti-scraping features, captchas that require a human to sit at computer all time and solve them, change IP or do manual data entry, making project too costly for the value of the data we can get.
Do not get angry at me if I fail scraping data from one website, just give me another website and I may succeed with it.
I know how useful is a phone or email database, for example an insurance company wants to spam emails of car owners posting listings in classifieds websites, but most classifieds websites protect seller phone number and contact email from being read by bots and spammed with unsolicited emails, by using a Contact button, or need to click a button to reveal email, or email is shown in an image rather than text format. In this case the job is more suitable for a child with lots of free time to write manually text from each image, than for us, skilled programmers busy with few dozens projects per month.
Advantages of my service and future updates
The main advantage of working with me is that once I create a database I can post on website to be purchased by multiple people, and offer everyone FREE updates for one year. When a new customer pay for database, if he require an update, I run scraper again and offer updated database for previous customers too, free of charge (this is valid for databases in my personal interest: cars worldwide, real estate of Singapore, and few more).
But if you ask me to scrap a website “just for you” outside of my fields of interest, you need to pay each time you want an update, 20-50% of the price you paid for initial database creation. While I usually give data only, if you need frequent updates I can give you scraper (an EXE file) to run on your own computer, at 2x-3x price of one-time scraping.
Can you make a database for our exclusive use, and not sell to anyone else?
I like web scraping jobs because I can publish databases on website for other people if are interested to purchase them too, generating a lifetime income with a small amount of time needed for regular updates.
BUT if you want to be exclusive user of a database, I will no longer like this job. You need to pay a price equivalent with the estimated sales for one year… and answer a big question: what I should do if someone else ask me for SAME data? Would be rude to say NO to the second customer just because a previous customer requested exclusivity (how I can “compile” again? I just need to sell the database I compiled for you), even if I say NO, he will pay another freelancer and obtain anyway the data I sold you exclusively.
In conclusion: exclusive use is nearly impossible, I can avoid publishing a database on website, but I reserve right to sell to other people if they ask for same kind of database.
Is web scraping legal?
The process of web scraping (making scripts that automate data extraction) is usually LEGAL, but using data extracted (manual or automatically) from one website for purpose of creating a competitor service, is usually ILLEGAL.
If the data been added by third-party volunteers (such as sellers in classifieds websites), there is no copyright. But if a person hardworked to compile data (even from free sources), compilation can be copyrighted, that person can hunt other people who pirate his work. Some websites contains dummy data (example: a bunch of cars having +/- 1 horsepower than official value) that can prove that you copied from them.
But most websites don’t care about having their data pirated, unless they do make business from it. For example: you can copy without fear Year-Make-Model breadcrumbs from a car insurance website for purpose of making similar navigation for your car accessories store, but you should not copy data from a website selling Excel for purpose of reselling data via API or vice-versa.
I did received Cease & Desist letter to stop selling a database that I created by scraping data from an API seller at insistence of a customer who could not use API and wanted to store data locally, and threatening me that if I don’t delete database from website I will be sued. Update: I talked with other people doing web scraping for years and they told me that received many Cease & Desist / takedown notifications, but never had a lawsuit. Because if you offer data freely accessible on your website, is very hard to make lawsuit (and win it) against people who copied data (except when data is accessible via login with paid subscription or selected members).
Early opinion: in 2012 when I started selling first time European Car Models & Engines Database sourced from AutoKatalog books is a copyright violation, but I came in conclusion that it is fine, because my databases is an original compilation writing data in a different data structure than the book, and it target online audience, while the AutoKatalog is a book sold in shops targeting car hobbyists. In case of America, Year-Make-Model is my original compilation sourced from Wikipedia and 3 more websites. I am doing each year over 100 sales without having a single person worrying about copyright.
Country matters: I had many customers in India asking me to scrap data from various websites. However, when someone from Europe or America ask me certain data that I do not have and I offer him to create required database by scraping from a website, some people bring me attention about legal issues of web scraping.
Funny case: someone offered to sell me for $2000 a car database that he claimed to have been creating it by working for 4 months, 8 hours per day, copy-pasting data from a website, with rights to resell on my website. From copyright point of view does NOT matter if you extracted data using an automatic software or typed every letter manually, as long you copied all data from single website your work is not original. He was probably not aware of scraping software. If you wasted few months doing something that could have been done in few hours using scraping software, you are an IDIOT (I was an idiot too doing such jobs before 2015 being not aware of scraping software, but small jobs only) and I am still doing in case of European database because I source data from books (offline sources), making an original product on the web.
Example of data extraction / scraping projects done and their price
Most scraping software save data in CSV format, but if I decide to publish on my website, I make XLS files with borders, colors, headers and other visual features to match the style of other products “Made by Teoalida” that give impression of work done with care.
India Car Database – source: www.carwale.com – Made in August 2015 from personal interest because of numerous people asking me about indian car database. Being my first scraping project, it took initially 8 days to figure out how to use import.io and do it, once my programmer partner made own universal scraper, time required to do each update was reduced to 3 hours. Over 3000 rows and 188 columns. Sold in 3 different packages 30, 60, 120 euro depending by number of columns. During first year it has been purchased by 8 people, I also made a FREE “make & model only” package, hoping to encourage customers to make a free purchase before paying for big database, but contrary happened. Once removing the free package, number of sales increased.
India Bike Database – source: www.bikewale.com – Made in January 2016 after 2nd person requested a database of bikes sold in India. One of easiest projects, having no drop-down boxes but plain links to each bike page. 250 records, price: 25 euro.
CarWale On-Road Prices – source: www.carwale.com – Made in January 2016 for a customer, a difficult project taking about 20 hours of coding in Visual Studio to make an application sending javascript requests to CarWale website to get price of each car in each city, we agreed for $300 of which $200 paid to my programmer, the scraper did 2 requests per second, so 3100 cars × 510 cities = 1632000 seconds = 226 hours needed to get all on-road prices, RTO tax and insurance. Had to keep scraper running for a month. In early 2016 this was OK but once more customers started to come I couldn’t do this anymore. I agreed with customer to reduce number of cities to 47 so scraping time was reduced to 4 days, and pay $50 per update. Due to GST in July 2017 customer said that this project is no longer required.
Skyscrapers Buildings Database – Made in November 2015 from personal interest, put for sale for $150 (15000 buildings) and turned into a marketing failure, 1 year passed and nobody purchased it (except a customer asking me for make US buildings database, see below). Took about 20 hours to compile manually list of cities with buildings over 100 meters, then list of buildings from these cities, then used import.io to automatically extract each building details. 15000+ buildings. They block my IP for 2 days if I access more than 3000 pages in one day, so data extraction with import.io (not able to change IP) was limited to 3000 buildings per day, which took about 1 hour daily for 6 days.
US Buildings Database – Made in November 2016 for a customer seeing above Skyscrapers database told me to make a similar databases with all types of buildings from USA, 160,000+ buildings, had to run over 100 batches of max 2000 buildings, now using my partner’s universal scraper from my computer, I could change IP after each batch, running again and again blocked URLs until I was able to get all buildings. 60 hours of work. Price: $600.
Singapore Condo Database – source: www.singaporeexpats.com – Made for a customer in 2015, took 3 hours and sold database with 2809 condos for $140.50 SGD. In one year several other people purchased.
Singapore Condo Database II – source: www.propertyguru.com.sg – Made for a customer in 2016. Apparently an easy project, having plain links to all condos, it turned impossible to do with import.io because of a fucking CAPTCHA appearing randomly after 10-50 pages extracted. My programmer spend 2 weekends in Visual Studio making a custom scraper that allow me to input CAPTCHA when needed, charged me $300 USD, and I sold database with 3176 condos for $317.60 SGD (about 240 USD), leaving me in loss, but because other customers have purchased it, profit came.
World countries database – source: The World Factbook – Made in 2017 from personal interest, a database with an impressive amount of 362 columns and only 268 rows. Took about 5 hours to write XPath codes for each column, and only 35 minutes to scrap data.
Mobile Phones Database – source: GSMarena.com – Made in August 2016 from personal interest. A simple project made with our universal scraper. During first year it has been purchased by over 10 people, this allowed me to provide FREE monthly updates, each scrap taking about 1 hour.
Australia car database – Made in June 2017 after a year of hiatus because I wasn’t sure if Australia can provide sufficient sale volume to cover my effort. Scraping was a headache because the source website use anti-scraping features that blocks my partner universal scraper. Had to use another scraper which was slow (12 seconds per page) and frequent crashes. Took 14 days to scrap all 90000+ cars, future updating is done by scraping only last year of cars. Price $450 with discounts offered for partial purchases. It had a happy turnout, during first year it over 10 people purchased it.
Chiptuning database – source: celtictuning.co.uk, br-performance.be, dyno-chiptuningfiles.com, made for a customer in February 2018 (CelticTuning), a simple project that took about 2 hours and price was $100. Several other people purchased it during a year.
Postal code scraping – a customer gave me a list of postal codes which I input in www.streetdirectory.com to get building name and street address (in Singapore every building have unique postal code).
Flickr scraping – a customer downloaded a large amount of car images from Flickr and realized that to use in his website he needs to specify author name, link to source page and link to Creative Commons license. I scraped this info, 223,000 images for 223 euro at 0.6 seconds per page.
Used cars images – a customer asked me to scrap an used cars website, to get image URL beside Make, Model, Year. Took only FEW HOURS and I got over 100.000 car images, all in same resolution. He told me to keep it private and do not publish or resell on website. So I am telling you only the idea. If anyone wants to scrap car images in this way, let me know what website to scrap!
Complete list of databases (note: I done few more projects not included in this list, because customers told me to NOT publish on website, or they are in fields unrelated to topics covered by my website so even if published, they won’t get sales).




I’m interested in getting data for Australia apartment projects. I understand that you are scrapping data from sites like guru and sgexpats. I saw this property website which has Australia listings. https://sohoapp.com/marketplace/for-sale-around-Sydney-in-Australia@-33,8688197-151,20929550000005
Do you have any database for new projects in major cities in AU like Sydney, Brisbane and Melbourne. Particularly looking for apartments, not houses.
Australia real estate is NOT in my personal interest, can I ask a friend to do this job instead of doing myself?
From PropertyGuru and SingaporeExpats I scraped their condo directories (static data) and NOT property listings for sale (variable data, with new properties posted daily and others deleted) As far I see SohoApp display only 20 listings, how do I see all listings? Since this is variable data, do you need one-time scrap or how often do you want updates?
I don’t know why did you posted comment in Housing in Singapore page, I moved to Web scraping page.
Here is a good article about this topic.
https://finddatalab.com/
I have 2 programmer less busy than me who were willing to do this large project, but it seems that customer wanted to have project done MYSELF and not by anyone else from my team. I wish you to stay 12h/day in front of computer (like me) and not doing anything else than serving all customers yourself (and still not able to serve all), how do you feel?
Chat started on Tuesday, October 27, 2020 9:43:57 PM
(9:43:57 PM) *** Visitor 34880592 has joined the chat ***
(9:43:59 PM) Teoalida (site owner): Hello visitor from United States, are you looking for a specific database? Let me know if I can help you!
(9:45:02 PM) Visitor 34880592: amazon
(9:45:12 PM) *** Teoalida has joined the chat ***
(9:45:12 PM) Teoalida: ??
(9:47:00 PM) Visitor 34880592: wanted to know how much it is for weekly runs…is it the same cost as you describe onthe site
(9:47:16 PM) Teoalida: what do you need more exactly from Amazon?
(9:47:32 PM) Visitor 34880592: all products all prices for the UK and US top seller lists
(9:48:07 PM) Teoalida: what do you mean “all products” since there are millions products on Amazon
(9:48:25 PM) Visitor 34880592: not on the top seller lists – 100 products by category
(9:49:04 PM) Visitor 34880592: but generally if the first collector is $X and we need it collected every day is the cost then $X * days ?
(9:52:03 PM) Teoalida: and because Amazon is a huge website, they can also invest in anti-scraping measures
(9:52:25 PM) Teoalida: few years ago I tried scraping didn’t succeded… I don’t remember what happened
(9:53:16 PM) Teoalida: anyway what do you want looks a huge job + monthly updates and NO use for anyone else
(9:53:35 PM) Teoalida: what I should do now is to refer you to a friend able to take such big jobs. How we can contact you?
(9:54:50 PM) Visitor 34880592: ok.
(9:56:00 PM) *** Visitor 34880592 has left ***
each website have a random number of pages, these prices are just relative and final price will be given at request.