
In 2013 I finished American Car Models List (Year-Make-Model), it’s time to start the next project: American Car Models Database with trims and technical specs! I wrote “Tell me WHICH SPECS are you looking for, and I will tell you if is possible! Excel sample available at request.“
My personal idea is 14 technical specs + year, make, model, trim, body… but I need to do a survey to ensure that is enough for american tastes, before wasting time developing a database that nobody wants it (July 2013). I made a SAMPLE in July 2013 but never published on website (except being shown in blurred screenshot) inviting people to contact me. I gave the Excel file ONLY to <10 people who have contacted me, and we discussed about it, thus helping me to make correct decisions.
FINAL sample file published in February 2014, full database available for sale in May 2014.
Original database made in 2014 that I was not able to update
All European databases plus American Year-Make-Model (without specifications), are compiled and updated manually by myself (1-person work, since 2003), data taken from books and typed in Excel, etc.
But this American Year-Make-Model-Trim-Specs is a 2-person work, for the first time I “cheated” and crawled a website = scraped data automatically with a program.
More exactly, I found that one of my customers was also a programmer, we agreed to exchange a free database (refunded his purchase) for helping me making a crawler for free, and crawl a website few times per year so I can provide regular updates. The job turned HARDER than he expected, first and second attempts it crawled only first trim of each model, the programmer had to rescript it 3 times to find every trim, 20 hours of work in C# in weekends, finished in April and gave me raw CSV data. Then, myself as a car expert, I spent just few hours enhancing data visually in Excel, deleted duplicates (cars accidentally crawled twice), fixed few fatal errors, filled some of the missing data, and launched database for sale in May 2014.
Final data sheet had 41425 rows, 28 columns.
Note: at 2015 recheck I found that each duplicate indicated one or more missing vehicles, about 1000 vehicles were missing, so even at 3rd attempt the crawler wasn’t finding EVERY vehicle.
After doing few sales over next months, I asked him to crawl again so I can update the database, but shit happened: the source website changed its architecture so the crawler was no longer able to find any car. It need to be rescripted, meantime the programmer started his own company and no longer had time to re-re-rescript my crawler every time I want an update.
What I can do now? Hire a dedicated programming company? I tried, but they are interested in MONEY, not in making a perfect job, charge me $1000+ (this is more than what I earned from sales of this particular database in whole 2014), full payment in advance, I have no guarantee that they do a good job from first attempt and probably will charge me additional money to re-re-rescript crawler (as happened with my programmer).
Instead of looking for a programming company and risk my money, I am looking to make a new deal of mutual benefit, with a customer with programmer skills, personally interested in car data who can script a crawler and modify it until it runs perfectly, without additional charges.
You code a crawler, give me in-page raw data or just list of URL, for FREE and I will give an Excel database back to you in about 1 week for FREE, enhanced, duplicates removed, errors corrected (with my car experience), filled up car dimensions, etc. All these at the cost of my time, FREE of charge for you!
Some people told me from start that crawling that website is too complex for their skills. From January to July 2015, 3 potential customers agreed to make the mutual deal, I gave them details what to crawl, two stopped replying, 3rd one which we agreed to PAY him some money beside giving free database, after 2 weeks he gave up due to complexity. FAIL!
Remaking the database in November 2015… and offer regular updates
After failed to find a good programmer to help me scraping a website in exchange of a FREE database, in August 2015 I found www.import.io allowing to scrap data myself. Extracting data from a specific list of pages only, import.io cannot crawl all pages of a website automatically. But this makes me able to update database myself, without being dependent by third-party programmers, in semi-manual, semi-automatic way.
Spent 50 hours of manual work: visit 5000 pages and copy-paste their URL (2015-2016 models as well as old models having duplicate cars that equal a missing cars), then let import.io running in background for 40 hours (in batches) and automatically extract data from each URL, then do manual improvements in Excel.
Was busy with The BIG Car Database for Europe until 17 October, so the actual update for America stated in 19 October and finished on 10 November (with a break 20-28 October).
46813 mode trims – November 2015.
Offered in 4 versions, trims and full specs, whole database and new cars only (unlike 2014 database in a single price option), the dimensions database is yet to be filtered and launched.
47860 model trims – May 2016.
Sales were slow at start, but since March they were rising so I did first update in May.
48864 model trims – September 2016 (except Ford F-Series and RAM)
I decided to do a new update after 4 months, and when almost finished adding URL of 1000+ additional models, import.io suspended my account and limited new sign ups to scraping 500 pages per month, making me unable to add data for the newly added cars. My programmer partner from Pakistan started developing own universal scraping software similar with import.io, which took over 1 month of coding in Visual Basic until it was running properly.
40978 model trims – November 2016 (added F-Series and RAM)
I released the September update, doing scraping with my partner software.
50468 model trims – 22 March 2017
After doing main yearly update for Car Models & Engines Database for Europe in february, I started doing an update for American database, between 10 and 22 March. I am sorry that took so much to release a new update.
50772 model trims – 26 May 2017
Partial update just for new cars, I made more scraping scripts that indicate me where 2018 models are launched, instead of checking all 2017 models from A to Z to see if 2018 model was launched to add it, I checked only models that were actually launched. Time required to add URL of new models decreased from 30 to 5 hours, allowing me to update more often!
1093 models, 8184 model years, 51716 model trims – 22 August 2017
Full update done between 13-14 August and scraping 15-20 August.
1098 models, 8293 model years, 52607 model trims – 14 November 2017
Full update done between 6-7 November and scraping 8-12 November.
1116 models, 8386 model years, 53367 model trims – 18 March 2018
Full update done between 10-11 November and scraping 12-17 November.
Adding all missing cars and guarantee completion in March 2018
My database still relied on the scraping done by Singapore programmer in 2014, which due to very complex model hierarchy of Edmunds website, he missed many styles and captured twice some styles. At November 2015 update I checked the duplicate cars which equal missed cars and added them, I never guaranteed that I included every car available on Edmunds, I was aware that there could be additional missing cars with no duplicate car that could indicated a missed cars.
New cars added since 2016 also had some missing styles, because I was looking for new model years launched and added the styles offered at initial launch, at future updates I wasn’t always checking models already launched to see if they added later additional styles.
To guarantee completion I would had to manually open each model, each year, etc and check the URLs. I started this job manually in December 2015 but took more than 10 hours just to do from Acura to Buick so I had to stop.
After I mastered my scraping skills and after Pakistan programmer made an universal scraping software for me in 2016, I was able to do check for missing cars easier. But I didn’t hurry.
After 18 March 2018 update with new cars, I started the check for missing models by tagging 1 trims/style of each model year and running them in scraping software to extract IDs of all trims/styles, compare list of styles from scraper with list of trims/styles in my database, quickly spotting where something is missing to add them. This job took about 50 hours during 7 days, I added 623 missing trims/styles from 1990-2018 plus 40 styles of 2019 models launched in March 2018. By this way I also put the trims in same order as they were displayed on Edmunds (with few exceptions) and added nice borders 1-pixel thick between years, 2 pixels between models, 3 pixels between makes.
I had a terrible LUCK to do this job between 20 and 26 March 2018 because on 30 March 2018 Edmunds removed the old individual pages for each trim/style, and due to the bug in new layout I wouldn’t have been able to do this job.
54030 model trims – 1 April 2018 (5 2019 models).
A major change in April 2018, scraping from JSON and features columns removed
In late 2016 or early 2017 Edmunds website introduced a new layout to display specs for up to 3 trims at once that could not be scraped with my programmer’s universal scraping software. The old pages of each individual trim/style remained on Edmunds and I continued to use them to scrap data from, until they were removed on 30 March 2018.
Now, the only solution to scrap data is from JSON file of style ID (example JSON), paid $200 to Pakistan programmer to make a JSON scraper that automatically create columns for every label found. If the old HTML pages of each style contained 20 category labels listing features in text form (thus my database had 20 columns of features), JSON file contains beside specifications, a large amount of features with true/false values, but the feature labels are not consistent between cars so scraping all cars generated a database with few thousands columns. Had to delete all features and stick on the 53 columns of specifications.
JSON file contain trim and description differently than what was previously in my database. JSON file does not contain year, make, model, requiring me to add this info manually. JSON file contain car price, allowing me to include price in my database for first time (requested by many customers). However JSON file do not contain image URL so I am sorry for all customers who bought this database for car photos.
The new layout of Edmunds contains several bugs, one of them is when you go to a car having multiple body styles, example https://www.edmunds.com/ford/f-150/2018/ it shows only trims of Regular Cab, when you select from SuperCab or SuperCrew then click Features, it switch back to Regular cab. On the old layout pages there was a drop-down box showing trims of all body styles. My programmer partner confirmed that is NOT POSSIBLE to get vehicle IDs of other body styles than 1st body style.
I emailed Edmunds to report this issue and the issue was fixed next month. Surprisingly the old individual pages for each trim/style appeared back on Edmunds, allowing me to return to previous database format that include photos and features, or maybe a combination between two formats.
1004 models, 8242 models years, 54486 model trims – 22 June 2018 (2019: 64 models years, 516 model trims).
1007 models, 8354 models years, 55337 model trims – 20 September 2018 (2019: 164 models years, 1343 model trims).
Features columns added back
Beside bringing back old pages, Edmunds also made an anti-scraping feature that blocks the universal scraper made by my programmer partner. In October 2018 he made another scraper just for Edmunds which allowed me to scrap old HTML pages again, adding back the 20 columns of features, image URL, old style Trim and Description, etc, expanding database from 62 to 86 columns.
Do note that this is NOT future-proof, Edmunds can remove old HTML pages again sooner or later. Also the scraping of HTML pages is much slower than scraping JSON, so to serve customers needing these 24 extra columns I need to spend 7 days each update instead of 2 if I were to update only the original 62 columns.
1046 models, 8411 models years, 55762 model trims – 10 November 2018 (2019: 215 models years, 1707 model trims).
1057 models, 8505 models years, 56394 model trims – 5 February 2019.
I paid my programmer partner to make a 3rd scraper, for https://www.edmunds.com/car-maintenance/guide-page.html that allow me getting car IDs faster. This reduce time required each update and allow me updating more often. Also instead of quarterly updates that add new models with their trims, and 1 yearly update that check all old models for possible missing trims launched later than initial model launch, now each quarterly update will add possible missing trims in old models.
1064 models, 8580 models years, 57169 model trims – 11 May 2019.
? models, ? model years, 57708 model trims – 6 August 2019. I started this update in July when I got 57703 model trims, but personal problems kept me away from business. I ran scraper on 6 august and after adding 539 rows on 7-8 august, making 57708 model trims, just for curiosity I tried to run scraper again on 8 August, finding another 200 model trims, after spending 3 hours to add them I ran scraper for 3rd time and found ~10 more. Seems that my update overlapped with a major update in Edmunds, I decided to NOT release update for my customers and wait ~7 days then run scraper again on 15 August, I found another ~100 cars.
1073 models, 8697 model years, 58044 model trims – 15 August 2019.
1038 models, 8740 model years, 58480 model trims – 22 September 2019.
1042 models, 8820 model years, 59121 model trims – 4 December 2019.
Edmunds changed JSON https://www.edmunds.com/gateway/api/vehicle/v4/styles/200677657/features-specs
1045 models, 8837 model years, 59303 model trims – 14 December 2019.
? models, 8878 model years, 59600 model trims – 14 February 2020.
Note: number of models and model years BEFORE March 2020 is slightly inaccurate because I counted it by MANUALLY indicating when a new model starts, and did few mistakes, instead of using an automated software to count unique Make/Model/Year combinations.
In March 2020 a customer asked me to add Pros & Cons from Edmunds review pages, by this way I added also an usable image for each model (some of you may have noticed that former image URLs for 2019> models were inaccessible). I was running scraper weekly to count cars towards anniversary update of 60,000 model trims.
13 Mar 2020 – 59795
23 Mar 2020 – 59815
02 Apr 2020 – 59852
07 Apr 2020 – 59876
15 Apr 2020 – 59888
21 Apr 2020 – 59913
28 Apr 2020 – 59948
04 May 2020 – 59988
Shortly after reaching 59988 cars on 4 May, Edmunds changed coding and my scrapers no longer worked. Me and my programmer partner we’re working together to solve this… this incident delayed this and my other projects with a week, and I published update on 21 May having cars launched until 18 May.
During this process I noticed that Edmunds also provide number of seats and invoice price (which some of you asked me to add and I answered that Edmunds does not provide that) actually they provided in JSON but outside of the main { } containing specifications, that’s why my programmer omitted them when created JSON scraper initially in May 2018. Overall Full Specs increased from 86 to 96 columns.
In April 2020 Edmunds removed old HTML page again (as they did 0n 30 March 2018). Several people who bought Basic Specs package asked me to give the Bonus columns too (country of production, car class, platform code) so I decided to make them available by default in Basic Specs package, at same time I removed Old naming and Colors columns because very few people used them.
In addition of Trims only, Basic Specs and Full Specs packages, for the anniversary update I created additional packages for Make & Model only, Year-Make-Model-Image, Year-Make-Model-Body-Dimensions.
63 makes, 1099 models, 8938 model years, 60029 model trims, 86720 engines – 18 May 2020.
63 makes, 1113 models, 9012 model years, 60414 model trims – 13 August 2020.
63 makes, 1115 models, 9102 model years, 61181 model trims, 88354 engines – 23 October 2020.
63 makes, 1115 models, 9149 model years, 61590 model trims, 88992 engines – 3 December 2020.
63 makes, 1115 models, 9207 model years, 62071 model trims – 23 January 2021.
63 makes, 1120 models, 9259 model years, 62441 model trims, ? – 28 March 2021.
63 makes, 1133 models, 9259 model years, 62865 model trims, 90237 engines – 6 June 2021.
63 makes, 1138>1137 models, 9385 model years, 63310 model trims, 91397 engines – 8 August 2021.
63 makes, 1139 models, 9434 model years, 63754 model trims, 92078 engines – 16 September 2021.
63 makes, 1143 models, 9511 model years, 64350 model trims – 17 November 2021.
63 makes, 1143 models, 9513 model years, 64352 model trims – 22 November 2021. Added 18 trims and cleaned database by deleting 14 trims that were showing 404 NOT FOUND.
63 makes, 1143 models, 9516 model years, 64366 model trims – 24 November 2021. Added 12 trims.
64 makes, 1151 models, 9575 model years, 64885 model trims – 19 January 2022.
65 makes, 1168 models, 9664 model years, 65456 model trims – 17 March 2022.
66 makes, 1179 models, 9719 model years, 65829 model trims – 11 June 2022.
66 makes, 1182 models, 9803 model years, 66400 model trims – 13 August 2022.
66 makes, 1182 models, 9883 model years, 67032 model trims – 1 October 2022
66 makes, 1186 models, 9975 model years, 67822 model trims – 16 December 2022
66 makes, 1191 models, 10054 model years, 68245 model trims – 12 February 2023
67 makes, 1204 models, 10119 model years, 68732 model trims – 26 May 2023
67 makes, 1209 models, 10205 model years, 69407 model trims – 30 July 2023
67 makes, 1212 models, 10300 model years, 70054 model trims – 20 September 2023
67 makes, 1217 models, 10387 model years, 70571 model trims – 1 December 2023
67 makes, 1220 models, 10448 model years, 71091 model trims – 16 February 2024
68 makes, 1232 models, 10518 model years, 71603 model trims – 18 May 2024
deleted paragraph
Make & Model and Year-Make-Model were originally made as custom sheet for a specific customer, but seeing that other people are interested in same thing, I made them public so everyone can purchase.
The dimensions database originated from an experiment made in 2015 for Lexus, manually filtering database to a single row per Year / Make / Model / Body combination, I did not made for all cars because it would have taken dozens hours of manual work and risk cannibalizing sales of bigger database, also I was undecided what to do in case of variable dimensions. In 2020 I figured out how to automatize this task using Excel formulas to generate min/max values for cars that have variable dimensions for same body style (example Ford F-150 with short and long bed), the job took just few hours. I hope that these databases will help me to get additional customers and NOT turn customers that could afford full specs database to the (cheaper) dimensions database and affect my income negatively…
For people looking for more columns I offer since December 2017 second American car database, with 230 columns but less historical coverage and less accuracy. Choose which suit you better.

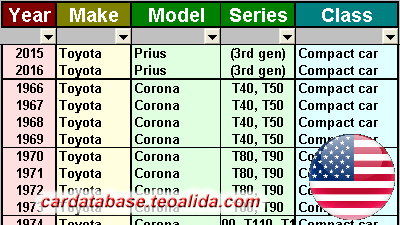
101362193 Chevrolet Express 2011 LS 3500 – Passenger Van (6.6L V8 Turbo Diesel 6-speed Automatic) Full-size van
You have listings for Chevrolet vans.
You do not have listings for GMC and Chevrolet 2500, and 3500 pickup trucks with 6.6L V8 Turbo Diesel.
Thank you